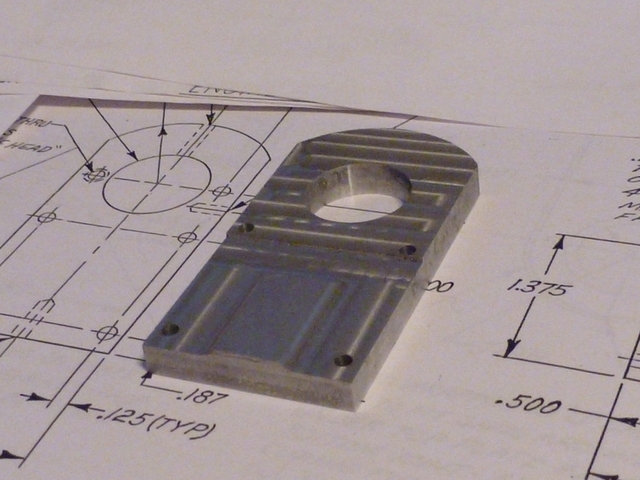
With a couple of steam engines under my belt, I've been wanting to build an
internal combustion type. I did some research and read some build logs here,
and it finally came down to Jerry Howell's Farm Boy or one of the Upshur farm
engines. After obtaining the plans, I really liked the Farm Boy, and I even
built a rocker arm and rocker arm post for it before the Upshur plans arrived.
After studying these, I decided to do a horizontal water-cooled Upshur farm
engine instead, as it seemed simpler to build.
I'm starting this log after having completed enough to have the confidence to
continue, so I'll be starting with a short burst of accumulated photos.
I make no claims to having photography skills, and if a photo is poorly
focused, I included it because I thought it essential to the story.
I welcome any and all criticism. I'm here to learn.
internal combustion type. I did some research and read some build logs here,
and it finally came down to Jerry Howell's Farm Boy or one of the Upshur farm
engines. After obtaining the plans, I really liked the Farm Boy, and I even
built a rocker arm and rocker arm post for it before the Upshur plans arrived.
After studying these, I decided to do a horizontal water-cooled Upshur farm
engine instead, as it seemed simpler to build.
I'm starting this log after having completed enough to have the confidence to
continue, so I'll be starting with a short burst of accumulated photos.
I make no claims to having photography skills, and if a photo is poorly
focused, I included it because I thought it essential to the story.
I welcome any and all criticism. I'm here to learn.